
No se necesita presuponer una distribución específica de las variables, usando tanto la escala de medida ordinal como métrica (razón o intervalo), aun cuando en la mayoría de los casos se aplica con propiedades en nivel ordinal de la variable dependiente. Se utiliza frecuentemente con situaciones donde la muestra es muy pequeña.
El algoritmo tiene como objetivo comparar dos variables relacionadas, y comprobar si existen o no diferencias apreciables. Es decir, si las discrepancia numéricas se pueden deber al azar o no.
La Ho asume que las medidas repetidas son iguales, en nuestro ejemplo que usaremos implica asumir que las observaciones son semejantes en el tiempo. Mientras la H1, es que las medidas repetidas son distintas (observaciones distintas).
Supongamos el siguiente caso sencillo, compuesto por 8 transectos, y 2 observaciones en el tiempo donde se determina el número de ejemplares de distintas especies que ocupan una zona intermareal asturiana, y que son visibles desde una distancia de 10 metros con cámaras subacuáticas. A continuación podemos ver un vídeo que ilustra lo dicho anteriormente anteriormente, correspondiente al muestreo de la playa de Cadavedo (400 metros) en la campaña observacional de 2014....
Ahora, supongamos que los datos son los siguientes:

Una vez implementados de forma adecuada en la base de datos del SPSS, y definidas las escalas de medida de las columnas numéricas, procederemos a elegir en el campo de analizar la opción de pruebas no paramétricas: una vez dentro del menú en el campo objetivo, se elige personalizar análisis, y luego rellenamos en el submenú campos con nuestras variables.

Posteriormente, en la pestaña de configuración elegimos seleccionar pruebas y pulsamos sobre el botón de Wilcoxon.

En los resultados podemos comprobar que existen diferencias significativas (p<0,05) de forma general,
 ....que podríamos formalmente decir que son observaciones temporales distintas para un Z=-2,023,p=0,043. No obstante, conviene recordar, que si utilizamos el nuevo criterio propuesto por Benjamin et al.(2017), la conclusión sería distinta. Por tanto, asumiríamos que no existen realmente esas diferencias.
....que podríamos formalmente decir que son observaciones temporales distintas para un Z=-2,023,p=0,043. No obstante, conviene recordar, que si utilizamos el nuevo criterio propuesto por Benjamin et al.(2017), la conclusión sería distinta. Por tanto, asumiríamos que no existen realmente esas diferencias.
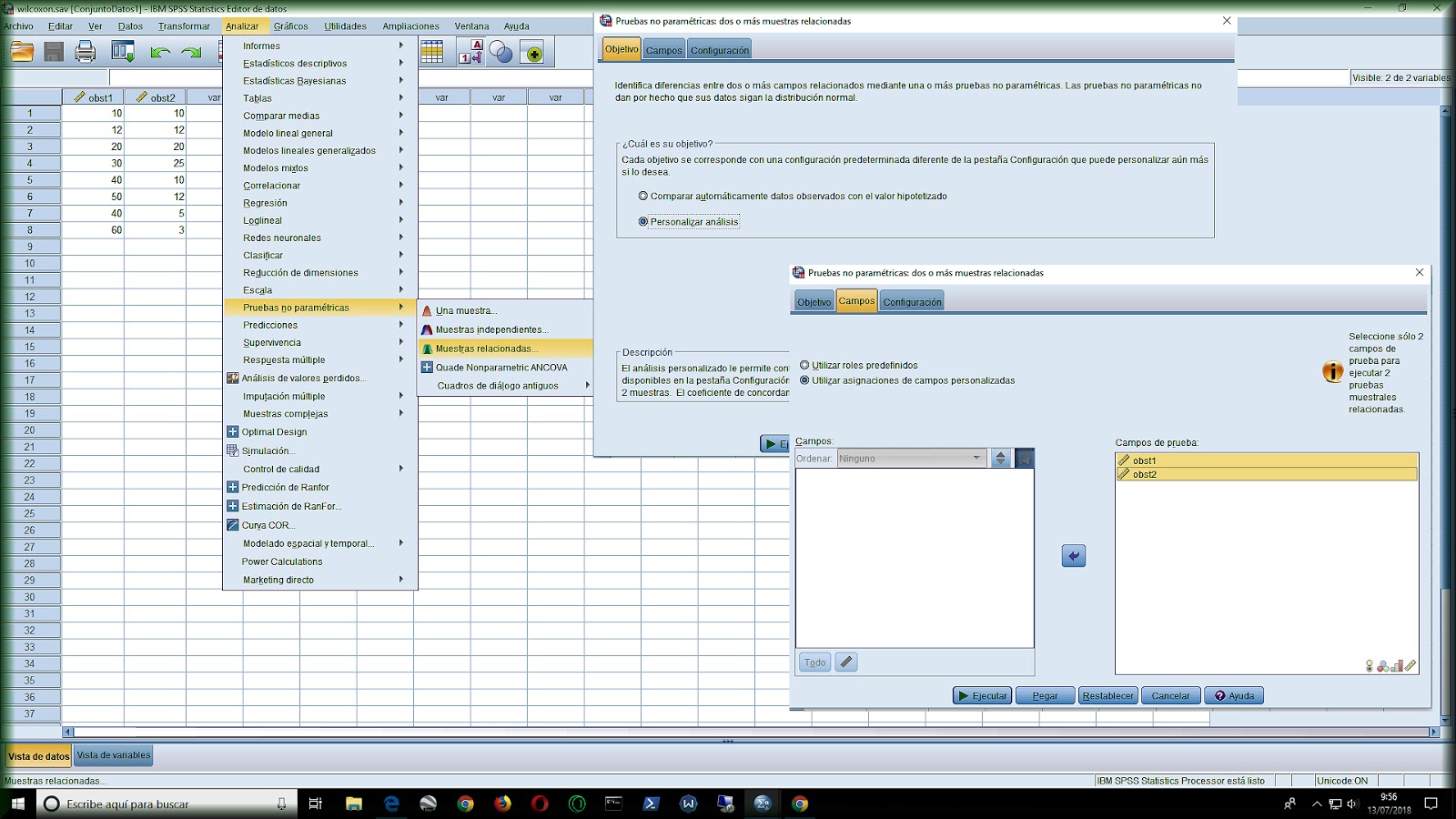
Posteriormente, en la pestaña de configuración elegimos seleccionar pruebas y pulsamos sobre el botón de Wilcoxon.


Para determinar el tamaño del efecto, aplicaríamos la fórmula general (usando la ventana de sintaxis):
COMPUTE r=Z/SQRT(n)
....donde Z es el estadístico de contraste del par de variables significativas, n el número total de observaciones (no el par de observaciones), y el tamaño del efecto indicado estadístico r.
Siendo posible también obtener el tamaño del efecto eta2 operando la expresión general r2.
Siendo posible también obtener el tamaño del efecto eta2 operando la expresión general r2.
En nuestro caso que sirve de ejemplo, para el par obst1-obst2, el estadístico estandarizado de contrastes es -2,023. Tomaremos su valor absoluto y operaremos:
COMPUTE r=2.023/SQRT(16)
....resultando un valor 0,506,
Es decir eta2= r2= 0,5062= 0,256
Es decir eta2= r2= 0,5062= 0,256
Siendo posible también obtener la d de Cohen usando procedimientos on line, como el implementado en:
https://www.psychometrica.de/effect_size.html
...resultando en nuestro caso el valor 1,1725
La valoración cualitativa de los resultados obtenidos de los tamaños de los efectos (d, r, eta2) se puede sustentar en esta tabla (Cohen, 1988; Hattie, 2009) :

Referencias.
*Benjamin, D. J., Berger, J., Johannesson, M., Nosek, B. A., Wagenmakers, E.-J., Berk, R., … Johnson, V. (2017, July 22). Redefine statistical significance. Retrieved from psyarxiv.com/mky9j
*Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2. Auflage). Hillsdale, NJ: Erlbaum.
*Hattie, J. (2009). Visible Learning. London: Routledge.
*Wilcoxon,F. (1945). Biometrics Bulletin, 1(6), 80-83.

Referencias.
*Benjamin, D. J., Berger, J., Johannesson, M., Nosek, B. A., Wagenmakers, E.-J., Berk, R., … Johnson, V. (2017, July 22). Redefine statistical significance. Retrieved from psyarxiv.com/mky9j
*Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2. Auflage). Hillsdale, NJ: Erlbaum.
*Hattie, J. (2009). Visible Learning. London: Routledge.
*Wilcoxon,F. (1945). Biometrics Bulletin, 1(6), 80-83.